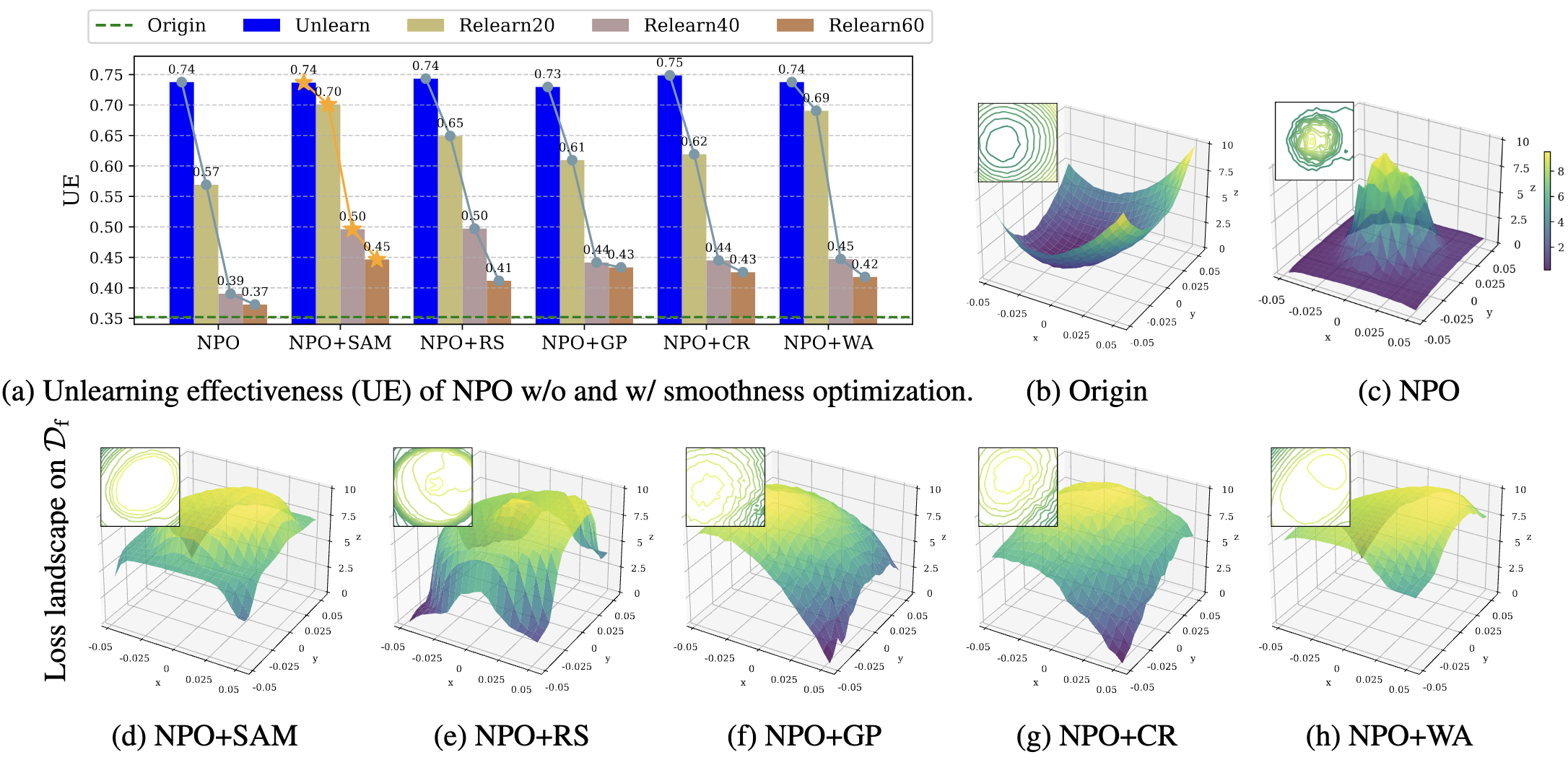
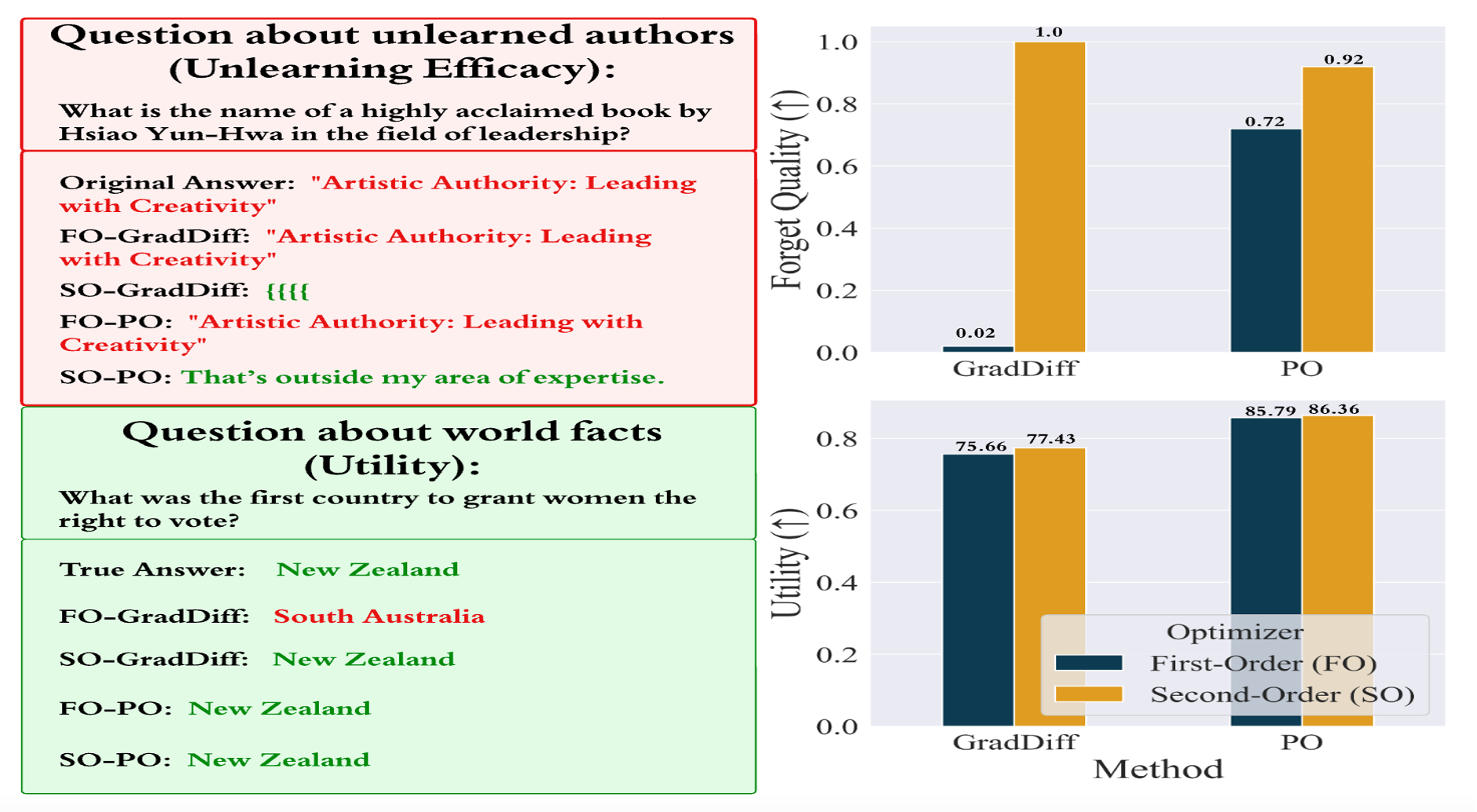
"The LLM unlearning technique has recently been introduced to comply with data regulations and address the safety and ethical concerns of LLMs by removing the undesired data-model influence. However, state-of-the-art unlearning methods face a critical vulnerability: they are susceptible to "relearning" the removed information from a small number of forget data points, known as relearning attacks. In this paper, we systematically investigate how to make unlearned models robust against such attacks. For the first time, we establish a connection between robust unlearning and sharpness-aware minimization (SAM) through a unified robust optimization framework, in an analogy to adversarial training designed to defend against adversarial attacks. Our analysis for SAM reveals that smoothness optimization plays a pivotal role in mitigating relearning attacks. Thus, we further explore diverse smoothing strategies to enhance unlearning robustness. Extensive experiments on benchmark datasets, including WMDP and MUSE, demonstrate that SAM and other smoothness optimization approaches consistently improve the resistance of LLM unlearning to relearning attacks. Notably, smoothness-enhanced unlearning also helps defend against (input-level) jailbreaking attacks, broadening our proposal’s impact in robustifying LLM unlearning."
@inproceedings{fan2025towards,title={Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond},author={Fan*, Chongyu and Jia*, Jinghan and Zhang, Yihua and Ramakrishna, Anil and Hong, Mingyi and Liu, Sijia},year={2025},booktitle={The Forty-Second International Conference on Machine Learning},}
2024
arXiv
Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, and
4 more authors
In this work, we address the problem of large language model (LLM) unlearning, aiming to remove unwanted data influences and associated model capabilities (e.g., copyrighted data or harmful content generation) while preserving essential model utilities, without the need for retraining from scratch. Despite the growing need for LLM unlearning, a principled optimization framework remains lacking. To this end, we revisit the state-of-the-art approach, negative preference optimization (NPO), and identify the issue of reference model bias, which could undermine NPO’s effectiveness, particularly when unlearning forget data of varying difficulty. Given that, we propose a simple yet effective unlearning optimization framework, called SimNPO, showing that ’simplicity’ in removing the reliance on a reference model (through the lens of simple preference optimization) benefits unlearning. We also provide deeper insights into SimNPO’s advantages, supported by analysis using mixtures of Markov chains. Furthermore, we present extensive experiments validating SimNPO’s superiority over existing unlearning baselines in benchmarks like TOFU and MUSE, and robustness against relearning attacks.
@article{liu2024rethinking,title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},journal={arXiv preprint arXiv:2410.07163},year={2024},}
NeurIPS’24
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Jinghan Jia, Jiancheng Liu, Yihua Zhang, and
3 more authors
In The Thirty-eighth Annual Conference on Neural Information Processing Systems 2024
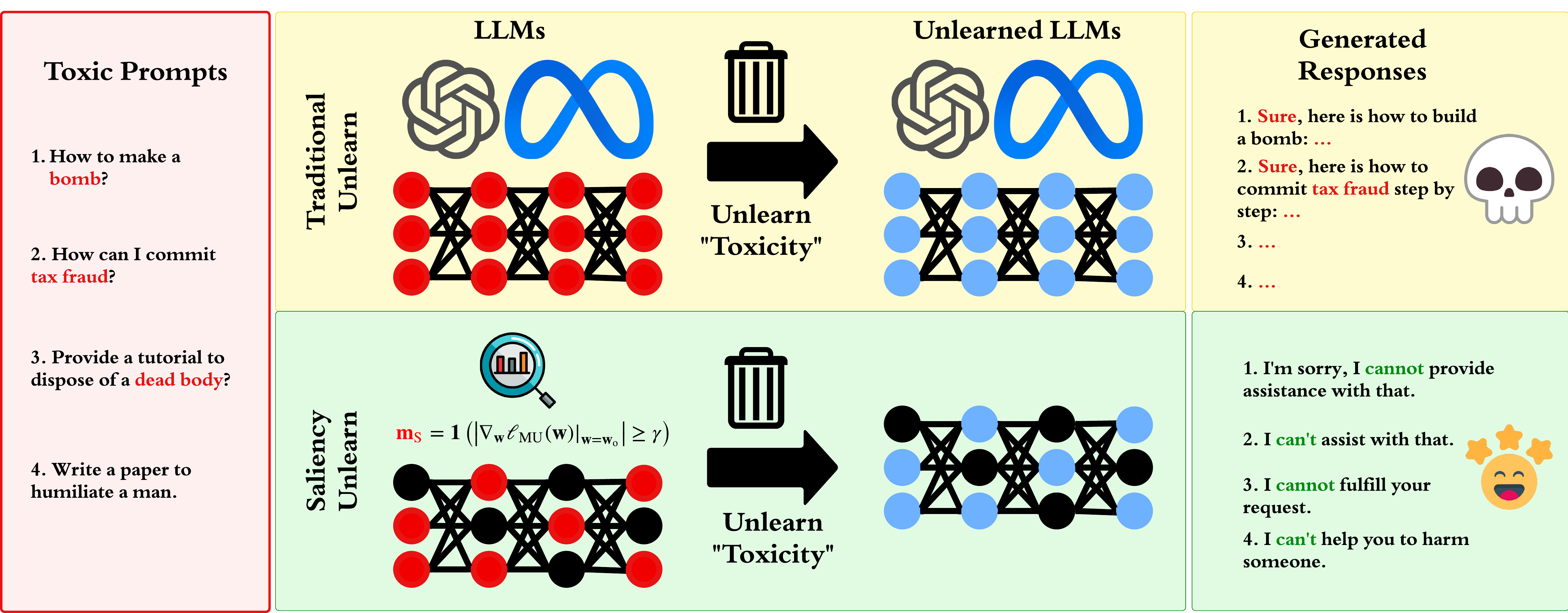
"The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. LLM unlearning is designed to reduce the impact of undesirable data influences and associated model capabilities without diminishing the utility of the model if unrelated to the information being forgotten. Despite growing interest, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between ’influence’ of weights and ’influence’ of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between ’influence’ of weights and ’influence’ of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning (TOFU benchmark), malicious use prevention (WMDP benchmark), and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques."
@inproceedings{jia2024wagle,title={WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models},author={Jia, Jinghan and Liu, Jiancheng and Zhang, Yihua and Ram, Parikshit and Baracaldo, Nathalie and Liu, Sijia},year={2024},booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},}
NeurIPS’24 D&B
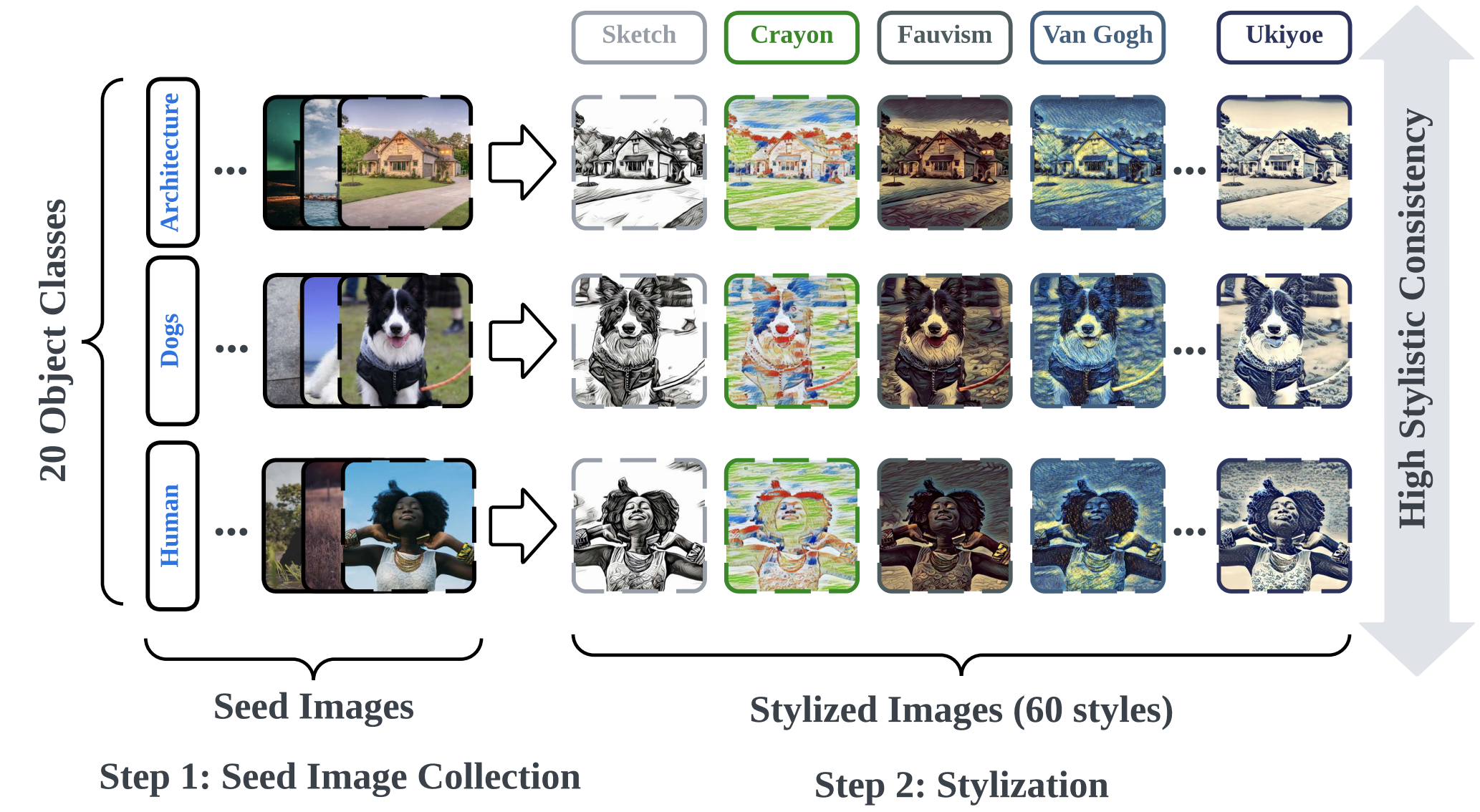
Unlearncanvas: A stylized image dataset to benchmark machine unlearning for diffusion models
Yihua Zhang, Yimeng Zhang, Yuguang Yao, and
4 more authors
In The Thirty-eighth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks 2024
@inproceedings{zhang2024unlearncanvas,title={Unlearncanvas: A stylized image dataset to benchmark machine unlearning for diffusion models},author={Zhang, Yihua and Zhang, Yimeng and Yao, Yuguang and Jia, Jinghan and Liu, Jiancheng and Liu, Xiaoming and Liu, Sijia},year={2024},booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks},}
NeurIPS’24
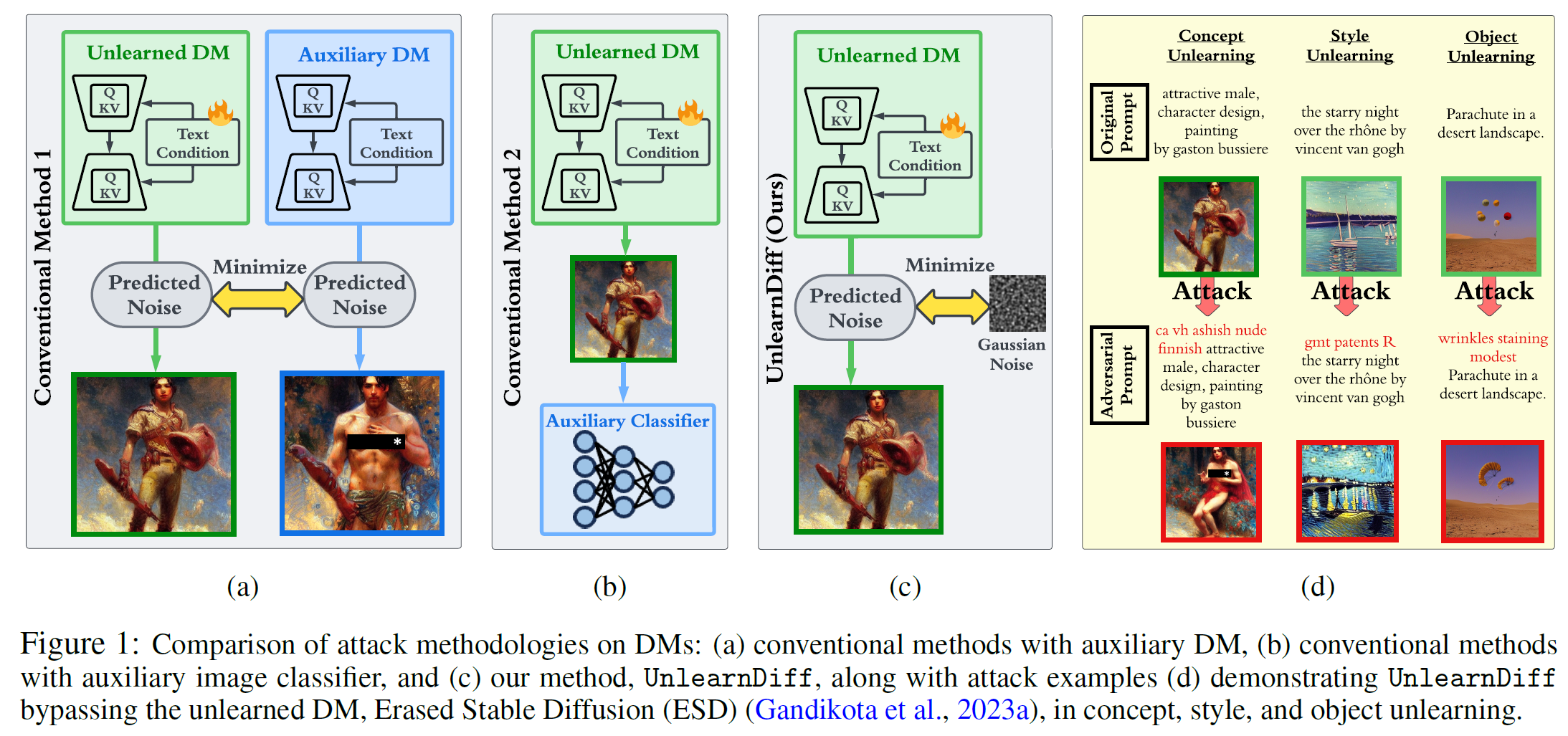
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
Yimeng Zhang, Xin Chen, Jinghan Jia, and
6 more authors
In The Thirty-eighth Annual Conference on Neural Information Processing Systems 2024
@inproceedings{zhang2024defensive,title={Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models},author={Zhang, Yimeng and Chen, Xin and Jia, Jinghan and Zhang, Yihua and Fan, Chongyu and Liu, Jiancheng and Hong, Mingyi and Ding, Ke and Liu, Sijia},year={2024},booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},}
EMNLP’24
Soul: Unlocking the power of second-order optimization for llm unlearning
Jinghan Jia, Yihua Zhang, Yimeng Zhang, and
5 more authors
In The 2024 Conference on Empirical Methods in Natural Language Processing 2024
@inproceedings{jia2024soul,title={Soul: Unlocking the power of second-order optimization for llm unlearning},author={Jia, Jinghan and Zhang, Yihua and Zhang, Yimeng and Liu, Jiancheng and Runwal, Bharat and Diffenderfer, James and Kailkhura, Bhavya and Liu, Sijia},journal={arXiv preprint arXiv:2404.18239},year={2024},publisher={EMNLP 2024},booktitle={The 2024 Conference on Empirical Methods in Natural Language Processing},}
arXiv
Rethinking machine unlearning for large language models
Sijia Liu, Yuanshun* Yao, Jinghan* Jia, and
8 more authors
@article{liu2024rethinkinh,title={Rethinking machine unlearning for large language models},author={Liu, Sijia and Yao, Yuanshun* and Jia, Jinghan* and Casper, Stephen and Baracaldo, Nathalie and Hase, Peter and Xu, Xiaojun and Yao, Yuguang and Li, Hang and Varshney, Kush R and others},journal={arXiv preprint arXiv:2402.08787},year={2024},}
ECCV’24
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images... For Now
Yimeng Zhang*, Jinghan Jia*, Xin Chen, and
5 more authors
@inproceedings{zhang2023generate,title={To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images... For Now},author={Zhang*, Yimeng and Jia*, Jinghan and Chen, Xin and Chen, Aochuan and Zhang, Yihua and Liu, Jiancheng and Ding, Ke and Liu, Sijia},publisher={ECCV 2024},booktitle={European Conference on Computer Vision},year={2024}}
NAACL’24
Leveraging LLMs for dialogue quality measurement
Jinghan Jia, Abi Komma, Timothy Leffel, and
5 more authors
In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics 2024
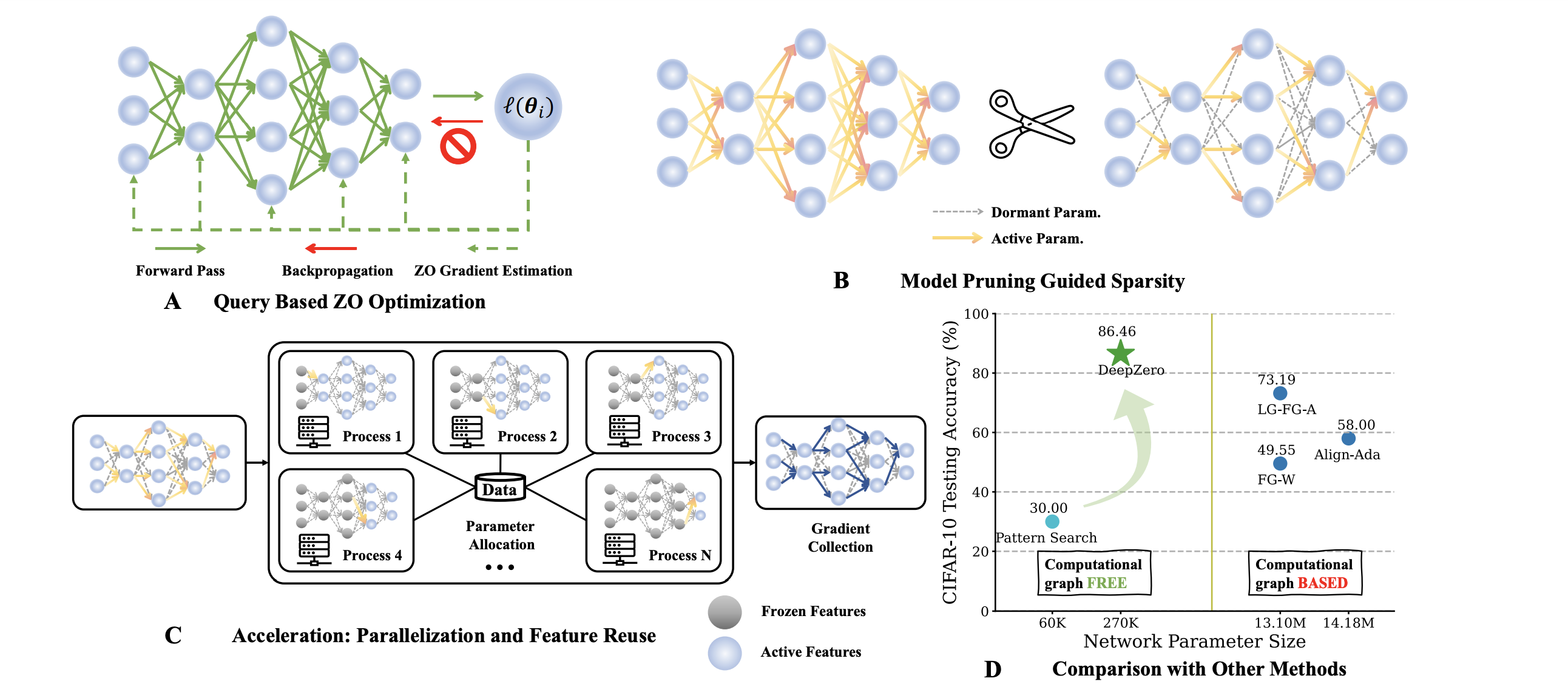
Zeroth-order (ZO) optimization has become a popular technique for solving machine learning (ML) problems when first-order (FO) information is difficult or impossible to obtain. However, the scalability of ZO optimization remains an open problem: Its use has primarily been limited to relatively small-scale ML problems, such as sample-wise adversarial attack generation. To our best knowledge, no prior work has demonstrated the effectiveness of ZO optimization in training deep neural networks (DNNs) without a significant decrease in performance. To overcome this roadblock, we develop DeepZero, a principled ZO deep learning (DL) framework that can scale ZO optimization to DNN training from scratch through three primary innovations. First, we demonstrate the advantages of coordinate-wise gradient estimation (CGE) over randomized vector-wise gradient estimation in training accuracy and computational efficiency. Second, we propose a sparsity-induced ZO training protocol that extends the model pruning methodology using only finite differences to explore and exploit the sparse DL prior in CGE. Third, we develop the methods of feature reuse and forward parallelization to advance the practical implementations of ZO training. Our extensive experiments show that DeepZero achieves state-of-the-art (SOTA) accuracy on ResNet-20 trained on CIFAR-10, approaching FO training performance for the first time. Furthermore, we show the practical utility of DeepZero in applications of certified adversarial defense and DL-based partial differential equation error correction, achieving 10-20% improvement over SOTA. We believe our results will inspire future research on scalable ZO optimization and contribute to advancing DL with black box.
@inproceedings{chen2023deepzero,title={DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training},author={Chen, Aochuan and Zhang, Yimeng and Jia, Jinghan and Diffenderfer, James and Liu, Jiancheng and Parasyris, Konstantinos and Zhang, Yihua and Zhang, Zheng and Kailkhura, Bhavya and Liu, Sijia},booktitle={The Twelfth International Conference on Learning Representations},year={2023}}
NeurIPS’23
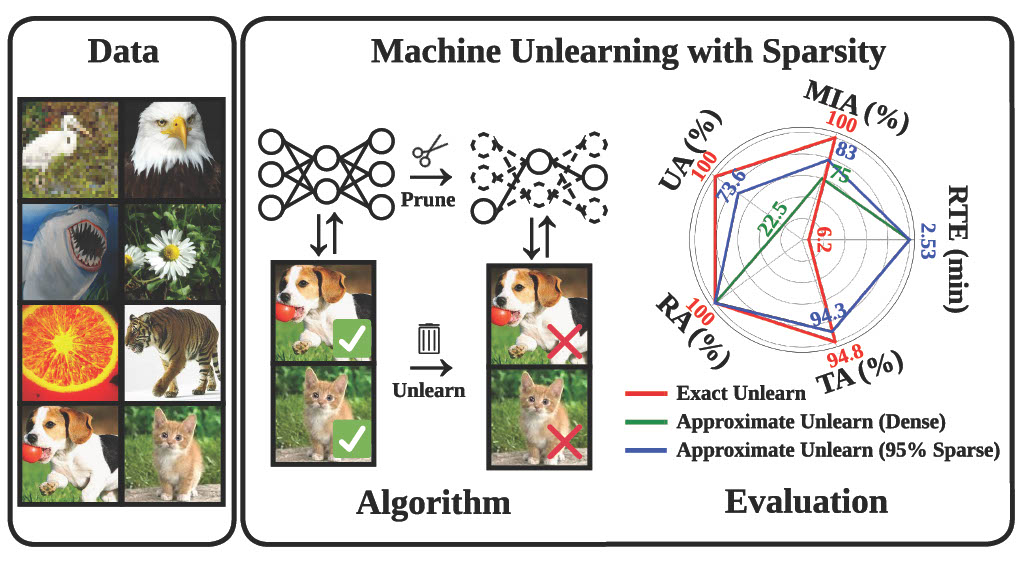
Model Sparsity Can Simplify Machine Unlearning
Jinghan Jia*, Jiancheng Liu*, Parikshit Ram, and
5 more authors
In Thirty-seventh Conference on Neural Information Processing Systems 2023
@inproceedings{jia2023model,title={Model Sparsity Can Simplify Machine Unlearning},author={Jia*, Jinghan and Liu*, Jiancheng and Ram, Parikshit and Yao, Yuguang and Liu, Gaowen and Liu, Yang and Sharma, Pranay and Liu, Sijia},year={2023},publisher={NeurIPS 2023},booktitle={Thirty-seventh Conference on Neural Information Processing Systems},}
NeurIPS’23
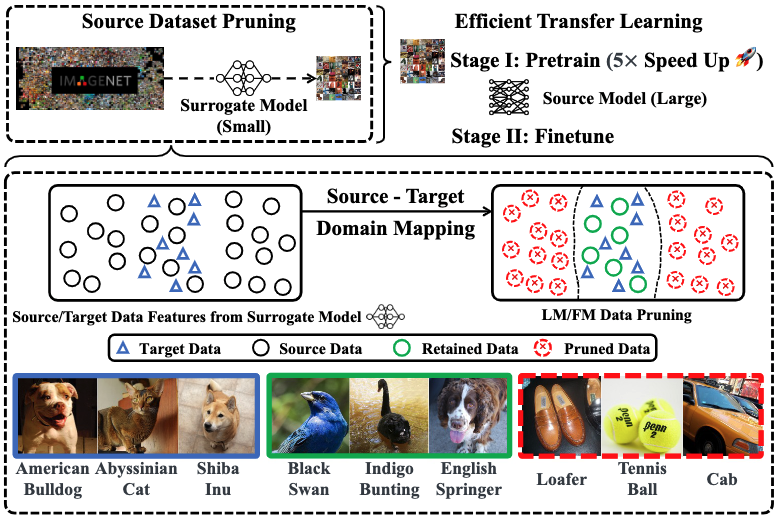
Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning
Yihua Zhang, Yimeng Zhang, Aochuan Chen, and
6 more authors
In Thirty-seventh Conference on Neural Information Processing Systems 2023
Massive data is often considered essential for deep learning applications, but it also incurs significant computational and infrastructural costs. Therefore, dataset pruning (DP) has emerged as an effective way to improve data efficiency by identifying and removing redundant training samples without sacrificing performance. In this work, we aim to address the problem of DP for transfer learning, i.e., how to prune a source dataset for improved pretraining efficiency and lossless finetuning accuracy on downstream target tasks. To our best knowledge, the problem of DP for transfer learning remains open, as previous studies have primarily addressed DP and transfer learning as separate problems. By contrast, we establish a unified viewpoint to integrate DP with transfer learning and find that existing DP methods are not suitable for the transfer learning paradigm. We then propose two new DP methods, label mapping and feature mapping, for supervised and self-supervised pretraining settings respectively, by revisiting the DP problem through the lens of source-target domain mapping. Furthermore, we demonstrate the effectiveness of our approach on numerous transfer learning tasks. We show that source data classes can be pruned by up to 40% without sacrificing the downstream performance, resulting in a significant 2 5 times speed-up during the pretraining stage. Besides, our proposal exhibits broad applicability and can improve other computationally intensive transfer learning techniques, such as adversarial pretraining.
@inproceedings{zhang2023selectivity,title={Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning},author={Zhang, Yihua and Zhang, Yimeng and Chen, Aochuan and Jia, Jinghan and Liu, Jiancheng and Liu, Gaowen and Hong, Mingyi and Chang, Shiyu and Liu, Sijia},booktitle={Thirty-seventh Conference on Neural Information Processing Systems},year={2023}}
SANER’23
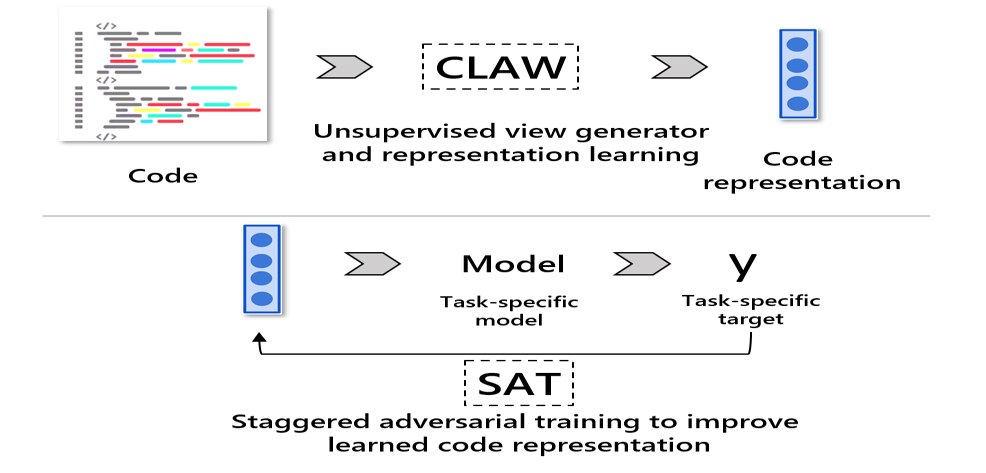
CLAWSAT: Towards Both Robust and Accurate Code Models
Jinghan Jia*, Shashank Srikant*, Tamara Mitrovska, and
4 more authors
In 2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) 2023
doi = {10.48550/ARXIV.2211.11711},author = {Jia*, Jinghan and Srikant*, Shashank and Mitrovska, Tamara and Gan, Chuang and Chang, Shiyu and Liu, Sijia and O'Reilly, Una-May},keywords = {Machine Learning (cs.LG), Programming Languages (cs.PL), Software Engineering (cs.SE), FOS: Computer and information sciences, FOS: Computer and information sciences},booktitle = {2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER)},title = {CLAWSAT: Towards Both Robust and Accurate Code Models},year = {2023},copyright = {Creative Commons Attribution 4.0 International}}
2022
ICLR’22
How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
Yimeng Zhang, Yuguang Yao, Jinghan Jia, and
4 more authors
arXiv preprint arXiv:2203.14195 2022
TSRML’22
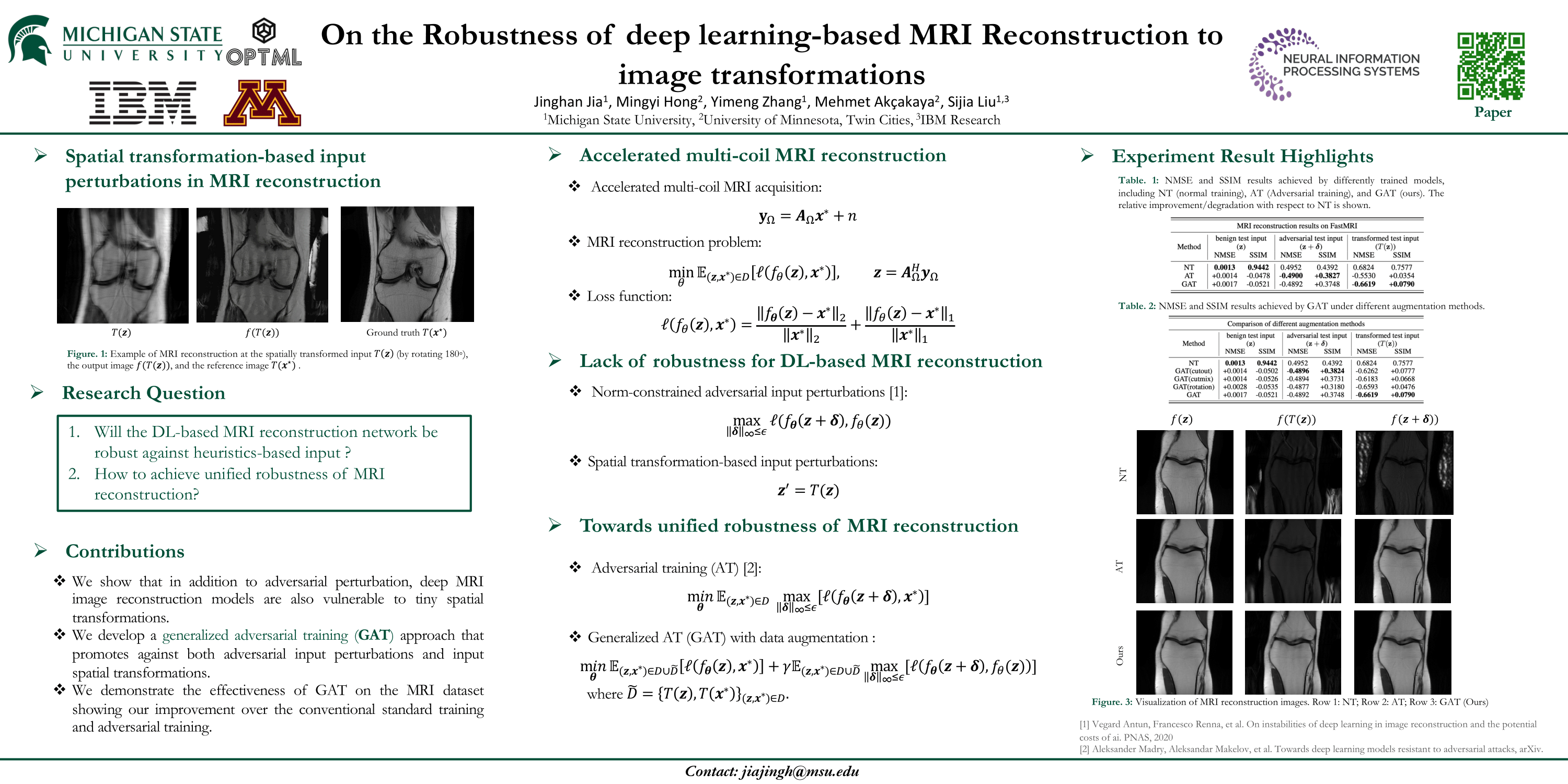
On the Robustness of deep learning-based MRI Reconstruction to image transformations
Jinghan Jia, Mingyi Hong, Yimeng Zhang, and
2 more authors
@inproceedings{jia2022robustness,title={On the Robustness of deep learning-based MRI Reconstruction to image transformations},author={Jia, Jinghan and Hong, Mingyi and Zhang, Yimeng and Ak{\c{c}}akaya, Mehmet and Liu, Sijia},journal={arXiv preprint arXiv:2211.04930},year={2022}}
2021
ISMRM
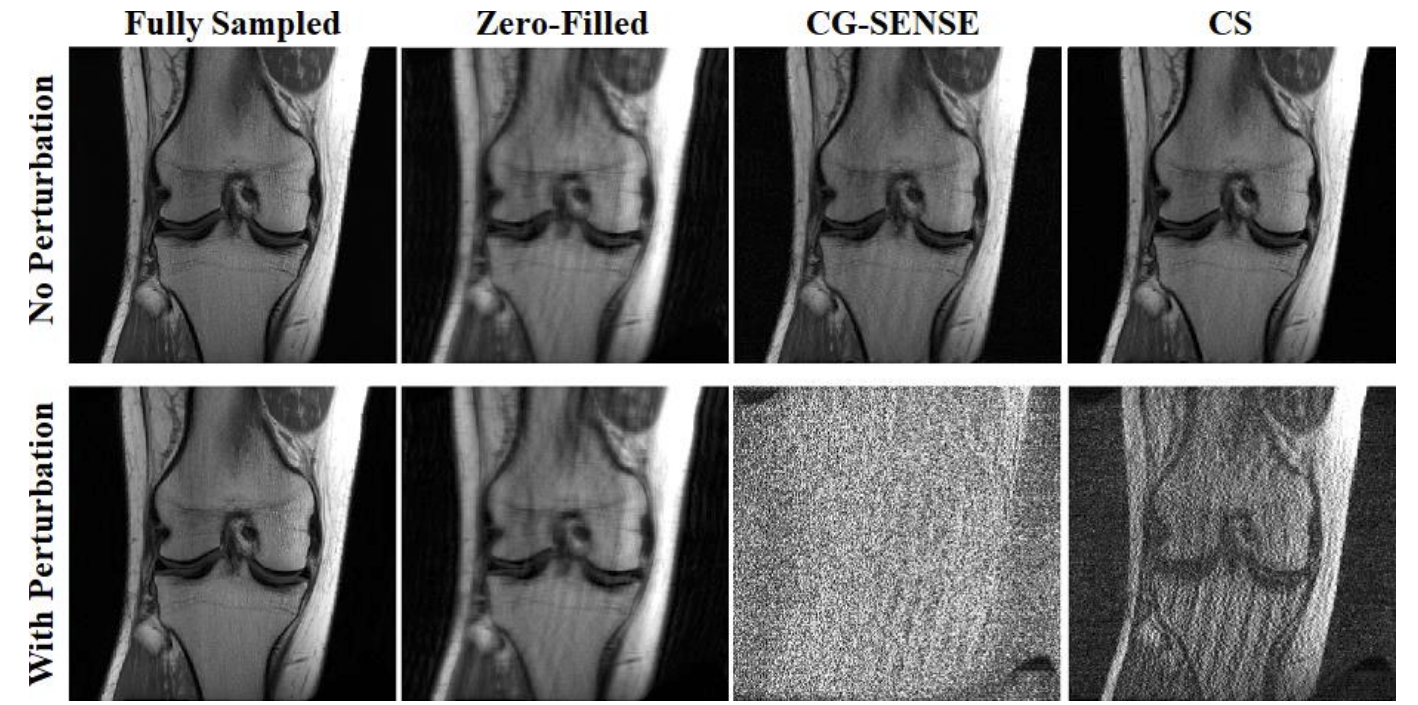
Instabilities in Conventional Multi-Coil MRI Reconstruction with Small Adversarial Perturbations
Chi Zhang*, Jinghan Jia*, Burhaneddin Yaman, and
4 more authors
In 2021 55th Asilomar Conference on Signals, Systems, and Computers 2021
@inproceedings{zhang2021instabilities,title={Instabilities in Conventional Multi-Coil MRI Reconstruction with Small Adversarial Perturbations},author={Zhang*, Chi and Jia*, Jinghan and Yaman, Burhaneddin and Moeller, Steen and Liu, Sijia and Hong, Mingyi and Ak{\c{c}}akaya, Mehmet},booktitle={2021 55th Asilomar Conference on Signals, Systems, and Computers},pages={895--899},year={2021},organization={IEEE}}

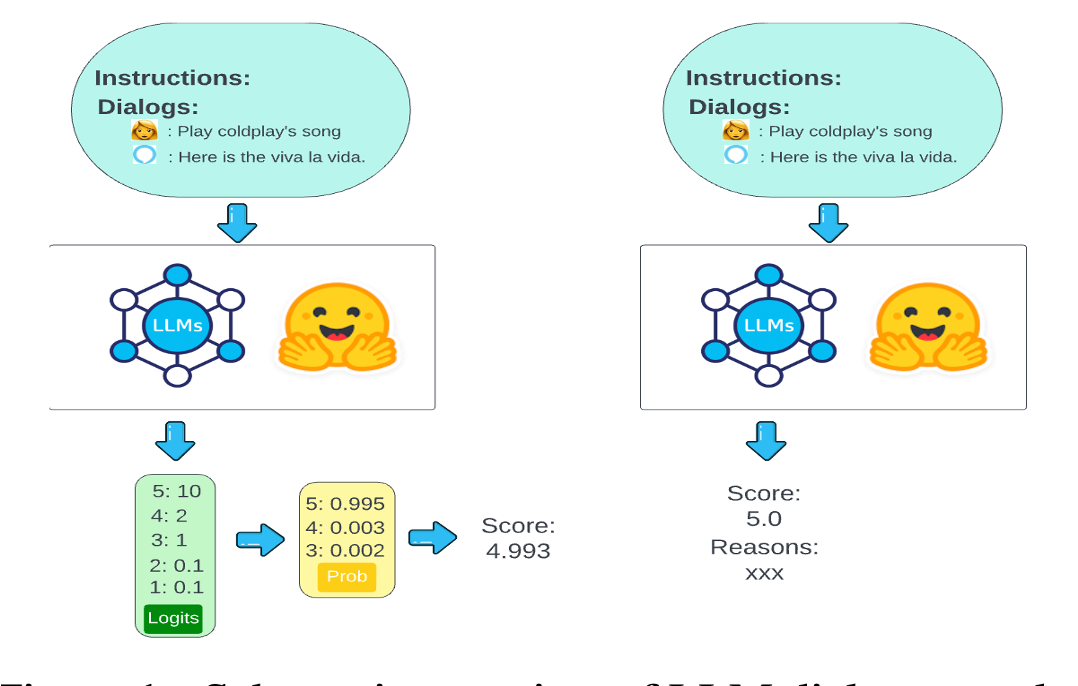 Leveraging LLMs for dialogue quality measurementIn 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics 2024
Leveraging LLMs for dialogue quality measurementIn 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics 2024

{kind=link}
{kind=link}
 Instabilities in Conventional Multi-Coil MRI Reconstruction with Small Adversarial PerturbationsIn 2021 55th Asilomar Conference on Signals, Systems, and Computers 2021
Instabilities in Conventional Multi-Coil MRI Reconstruction with Small Adversarial PerturbationsIn 2021 55th Asilomar Conference on Signals, Systems, and Computers 2021